Note: Code Updated and docmented in the article application/xhtml+xml Part Deux
Iamacamera.org is now serving its valid XHTML 1.1 via the W3C recommended MIME type to those browsers that support it. And it looks like we will all be doing something like this for the next few years at least.
The Story So Far
When a web page is served from a website and received by a browser, the web server indicates a "MIME type" of the file that is being sent over the internet to the browser. If a JPEG file is being sent, then the MIME type would be image/jpeg. Web pages themselves -- the HTML parts -- are sent with MIME text/html.
That is until XHTML 1.1. Now with XHTML 1.1, the Internet Standards state that the XHTML portion of a web page SHOULD (and even the word "SHOULD" is defined) be sent with MIME type application/xhtml+xml.
No big deal right? Well...there's a problem. When you send any, really, any XHTML web page to Microsoft Internet Explorer 6 (IE6) with the MIME type application/xhtml+xml guess what happens? IE displays a dialog box like this:
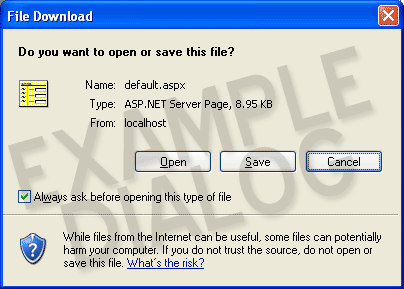
IE doesn't recognize what type of file is being sent, so it displays this generic dialog box asking, in essence, "What do you want to do with this file?"
Sending with application/xhtml+xml will cause everyone with IE6 to see this dialog on every page. Every page. On your entire website. In effect, your website can no longer be viewed in any shape or form by, oh, a couple hundred million internet citizens.
What about the other browsers?
Opera, Firefox and others, on the other hand, will display the web page in accordance to W3C standards - so long as you have well-formed XHTML and the correct namespace (the xmlns attribute below) defined in your HTML element's opening tag.
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
Standards Dilemma
So what's a web designer to do? If we wait until 99% of the browsers on the internet support the MIME type, we will still darken our entire site to over a million internet citizens. If we wait until 99.9% of internet browsers support the correct MIME type, we'll be waiting well past the 2012 Olympics because as of this writing, Chris Wilson of the IE7 development team at Microsoft has stated that IE7 will not support the application/xhtml+xml MIME type either!
One course of action would be to simply serve up XHTML 1.1 web pages as text/html to all browsers. That's what I did for a while. This angers two crowds:
- W3C standards purists
- Makers and users of the browsers that actually support the correct MIME type
The purists will be forced to come around eventually -- you can't ignore hundreds of millions of browsers. To appease the second crowd, there's Content Negotiation.
There are ways to serve the correct MIME type to Opera, Firefox, et al but serve text/html to IE et al that don't support it. This is called Dynamic MIME Support Detection or Content Negotiation. The concept is quite simple. From the web server's viewpoint: if the browser requesting a web page supports the application/xhtml+xml MIME type, send it back with that MIME type. If it doesn't support the correct MIME type, send the web page back old style, as text/html.
Content Negotiation C# Style
The folks at Microsoft are quite aware of this problem and have offered a solution. Listing 3 in an MSDN article written by Stephen Walther suggests how, at a server level, you can configure the global.aspx file to send back different MIME types to different browsers.
Barry Dorrans of idunno.org finds fault with the MSDN code and offers an improvement to the global.aspx solution (web page deleted) on his site.
My Solution
My solution for Vine Type is embedded in the ASP.NET Dynamic Link Library (DLL). This solution provides increased granularity by affecting only the pages served up by that particular DLL, and offers simplified deployment. It lacks, however, the flexibility of a configuration file change. I don't view either method as better than the other, just another option for programmers.
I placed this C# code in the Page_Load() method to ensure that MIME is set for every page created.
// the code previously shown here has been improved.
// the updated code is found in a follow-up article
Visit the follow-up article
Request.AcceptTypes is a string array sent by the browser requesting a page. The array contains strings of MIME types that the browser accepts. Cool! This simplifies our life.
Iterate through the strings searching for a match held in the strAppXhtmlXml variable. If found, set the Content.Type (ie MIME type) of the Response object to the standards-conforming value, then bail out of the foreach loop.
If we iterate through all the supported MIME types (IE6 returns only one string "*/*") without a match, then the Response will be sent back as text/html.
W3C Standards Purists
Remember the W3C standards purists above? They will point out that we are still sending out XHTML 1.1 via a non-recommended MIME type. If your conscience can handle only 100% conformance, then you might want to take a look at what Jesper Tverskov is doing.
For the ultimate in W3C standards conformance, Jesper offers C# code that changes both MIME and DOCTYPE (web page deleted). So when Opera or Firefox request a page, they get XHTML 1.1 served as application/xhtml+xml MIME. When IE6 requests a page, it gets XHTML 1.0 Strict served as text/html MIME. 100% conformance. And something I just might look into.


Comments
In most existing tools,
application/xhtml+xmlis a tough act to maintain.I wouldn't worry in the slightest about "degrading" to
text/htmlfor those browsers which can't handle the real thing. There is nothing about your content that will screw up (or, at least, fail to degrade gracefully) when served astext/html.On the other hand, your content-negotiation script leaves a little to be desired, as it ignores q-values. Theoretically (as far as I can tell, despite much discussion, this is purely theoretical), a UA could specify
application/xhtml+xmlwithq=0, in which case, you should not send it that MIME type.Thanks for the heads-up on this, Jacques. Q-values? Apparently, I have some more learning ahead of me. I'll look into Q-values right away. Thanks! (Hmmm. Q-values?!)
I wouldn't waste too much time with q-values (a mostly academic exercise). Nor would I spend any time switching DOCTYPEs based on MIME-type (an incredibly boneheaded idea).
If anything, I'd spend my time figuring out how to insure well-formedness. As I said, that's not a trivial task, unless your CMS was designed, from the ground up, with XML in mind.
Jacques, I'm glad to hear that q-values are not prominent on radar screens. The DOCTYPE switch did seem rather extreme to me also. As for a CMS being designed from the ground up with XML in mind well... yeah, it was.
It's not so much that it's "extreme"; it's that it's wrong.
When served as
application/xhtml+xml, the only function of the DOCTYPE declaration is that it's used by clients for resolving named entities. Not, mind you, by parsing the DTD. Browsers use a table of pseudo-DTDs for known DOCTYPEs. Use an unsupported DOCTYPE, and you're restricted to using the 5 "safe" named entities;&nbsp;generates a well-formedness error.If you want to use named entities in XHTML (a bad idea, but not an "invalid" one), then you need to declare a DOCTYPE supported by all the clients you're sending
application/xhtml+xml.When served as
text/html, the document is parsed as tag-soup, independent of the declared DOCTYPE. The only function of the DOCTYPE declaration is to switch rendering modes. For that purpose, XHTML 1.1 and XHTML 1.0 STRICT both invoke Standards-Mode rendering in all browsers that support "DOCTYPE-switching" of rendering mode.The one place where the actual choice of DOCTYPE makes a difference is when you validate the document. Validating the document under one DOCTYPE, and then serving it (otherwise unaltered) under another DOCTYPE vitiates the whole point of validation in the first place.
Cool!
Jacques,
I really do appreciate you crashing my site. (Just this article, actually.) Sending the invalid characters was quite an interesting edge case. And as you see, I haven't been validating input as well as I should.
I'm validating better now. I allowed those invalid characters to get into the XML comment file, but I'm doing some extra checks now to make sure what gets into the comment file is serve-able.
Also, I noticed that the Markdown blockquotes weren't getting transformed correctly, but that's fixed now also.
I see what you mean by "concentrate on well-formedness" -- there's a lot of rules to deal with.
Markdown (Vine Type allows HTML input but not HTML comments) has simplified well-formedness checking to a great extent. Your illegal characters today got into the comment XML file and generated an error when loading them into the XML document.
Now, when comments come in, I convert them via Markdown and load them into a test XML document. if the load fails, then your comment is not saved into the comment file and you will now see an error message.
I'm hoping this will catch the majority of error cases; I figure if the Markdown transformation can be loaded once, it's valid enough to save to the comment xml file.
Thanks for helping to test it.
Sorry 'bout that. I really didn't intend for quite so ... umh ... dramatic an effect.
But, yeah, once ill-formed content creeps into your CMS, the effect isn't pretty.
Illegal characters are always a good thing to test for. Some Markdown implementations produce ill-formed content when you do things like nest blockquotes. (I won't try that here; wouldn't want to wear out my welcome.)
But I am impressed that you really are using XML internally. Once you've licked the gnarly problem of validating your input, getting well-formed output should be a snap.
Kudos.
Jacques,
Not a problem here. I'd rather find this stuff before forty or fifty people download it and then have to upgrade.
as for the nesting...
And thanks for the encouragement.